
Introduction
This is a creative workflow built on ComfyUI and deeply integrated with the WanVideo plug-in of Ali Tongyi Wanxiang. First, the "Load image" and "Load WanVideo to TextDecoder" nodes start the material loading and introduce the image and video materials into the workflow. Subsequently, multiple key nodes such as WanVideo Loader and WanVideo TextDecoder relay to complete the fine processing such as model loading and parameter configuration, giving new creative possibilities to the materials. Then, through the careful carving of color matching, image stitching and other links, the material achieves a gorgeous transformation from static to dynamic. Finally, after a series of operations, video synthesis is a natural result, bringing creators visual expressions beyond imagination.
Wan-Video
a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. Wan2.1 offers these key features:
- 👍 SOTA Performance: Wan2.1 consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
- 👍 Supports Consumer-grade GPUs: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without optimization techniques like quantization). Its performance is even comparable to some closed-source models.
- 👍 Multiple Tasks: Wan2.1 excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
- 👍 Visual Text Generation: Wan2.1 is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
- 👍 Powerful Video VAE: Wan-VAE delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
https://github.com/Wan-Video/Wan2.1
https://huggingface.co/Kijai/WanVideo_comfy
Recommended machine:Ultra-PRO
Workflow Overview

How to use this workflow
This workflow is divided into two parts. Open the required part as needed and bypass the other one. If both are opened at the same time, a large amount of video memory will be consumed and the running speed will be nearly half an hour. Choose carefully!
Part 1: Text2Video
Step 1: Input the Prompt
Prompt supports Chinese and English. After testing, the recognition ability of Chinese is better than that of English.

Step 2: Input the Prompt
The Black one:
num_frames is related to the video length, under 81 frames doesn't seem to work
The minimum screen ratio is 512*512, otherwise it will cause image blur
The Purole one:
Improve video quality custom_node
https://oahzxl.github.io/Enhance_A_Video/
The blue one:
Video acceleration custom_node
https://github.com/kijai/ComfyUI-WanVideoWrapper

Step 3: Sampling parameter setting
When step=25, the video effect is already very fine. If you need to make a video with more elements such as the starry sky or flowers, it is recommended to set the step to more than 35

Step 4: Get Video
You can change the video length by setting frame_rate or num_frames (in WanVideo Empty Embeds). Video length = num_frames/frame_rate

Part 2: Img2Video
Step 1: Load Image

Step 2: Adjust Video parameters
Under 81 frames doesn't seem to work
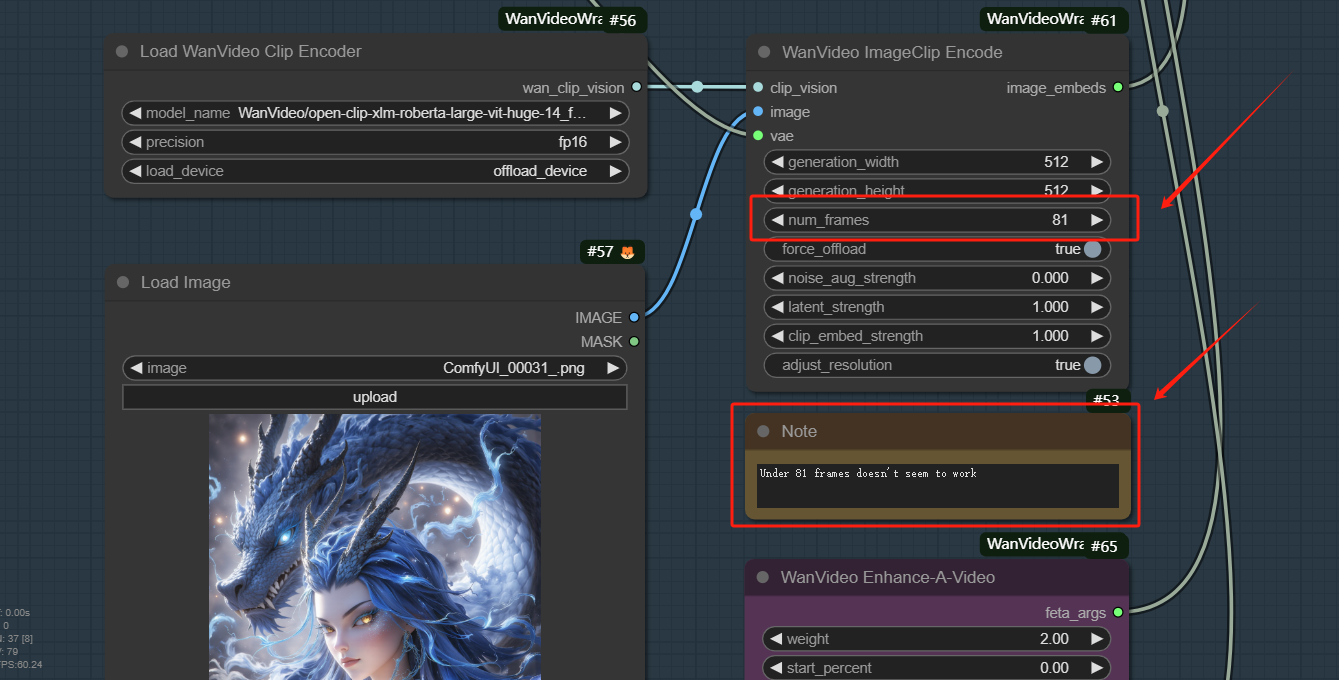
Step 3: Input the Prompt
No need to describe the entire picture in detail, just enter key information such as lens, action, etc.

Step 4: Set the number of sampler steps
When I was testing, the effect of generating a two-dimensional video was very good when step=30, and the real person would have a bad face; when step=50, the real person's facial texture gradually became clear, and there was a small probability of drawing a card

Step 5: Get Video
You can change the video length by setting frame_rate or num_frames (in WanVideo Empty Embeds). Video length = num_frames/frame_rate
